
–
Vorwort zur Reihe „KI-Tools für Einfache Sprache“
Was kann künstliche Intelligenz (KI) für die Einfache Sprache leisten? Wir haben bereits das Programm ChatGPT (siehe Blogs [1] [2] [3]) untersucht. Nun verfolgen wir, wie KI praktisch eingesetzt wird, um Texte leicht verständlich zu machen. Dazu testen wir neue KI-Tools, die öffentlich zugänglich sind. Besonders analysieren wir die sprachliche Qualität dieser Tools. Hierfür dienten uns bisher die Merkmale der Einfache Sprache (vgl. ABC der Einfachen Sprache) und die Leistungen von ChatGPT als Messlatte. In den folgenden Tests werden wir die neuen Normen für Einfache Sprache in die Analyse einbeziehen. Wir wollen mit diesen Tests zur Diskussion anregen: Was sind die Stärken und die Schwächen dieser Tools? Für welche Zielgruppen und Zwecke sind sie geeignet? Wie kann man die Qualität der erzeugten Texte verbessern?
Unsere Reihe begann mit dem KI-Tool vom Fußballclub St. Pauli, gefolgt von zwei Modellen der Textanalyse, die KI zum Vereinfachen der Sprache einsetzen: capito digital und Wortliga. Als Nächstes vergleichen wir die Leistungen von Google Chatbot Bard (heißt jetzt Gemini) und von ChatGPT in der Version GPT-4.
PS: Der Chatbot Bard wurde im Februar 2024 in Gemini umbenannt.
–
Vergleich der Leistungen von Bard und GPT-4 für die Einfache Sprache
Unsere vergleichende Analyse soll drei Fragen beantworten:
A. Wie funktionieren Bard und GPT-4 als KI-Programme für Einfache Sprache?
B. Können Bard und GPT-4 die Anforderungen an Einfache Sprache erfüllen?
C. Wie bewerten wir die Leistungen von Bard und GPT-4 für die Einfache Sprache?
A. Wie funktionieren Bard und GPT-4 als KI-Programme für Einfache Sprache?
Bard und GPT-4 sind vielseitige KI-Programme. Sie können viel mehr als Texte schreiben und übersetzen. Doch sie sind auch einsetzbar für Einfache Sprache. Bard wird genauso wie GPT-4 mit Aufforderungen (Prompts) gesteuert. Damit können sie beliebige Texte erzeugen: auf unterschiedlichem Sprachniveau, für besondere Zielgruppen und Zwecke, ausführlich oder zusammengefasst. Insofern übertreffen sie die speziell entwickelten KI-Tools für Einfache oder Leichte Sprache. Allerdings verlangen sie vom Nutzer besondere Fähigkeiten und Erfahrung, vor allem beim Formulieren von Prompts. Das heißt, Bard und GPT-4 können Einfache Sprache nur im Dialog mit kompetenten Nutzern erzeugen.
Die besten Ergebnisse erzielten wir bei GPT-4 mit folgender Aufforderung: „Schreibe diesen Text in Einfacher Sprache. Verwende dabei nur kurze Wörter, kurze Sätze und aktive Sprache (vgl. Blog 3 zu KI).“ Diese Aufforderung nutzen wir auch bei Bard.
Für die Übersetzungen haben wir, wir bei den anderen Tests, fünf Ausgangstexte zu verschiedenen Themen und auf unterschiedlichem Niveau verwendet:
- Käuferschutz bei PayPal (Auszug aus den Nutzungsbedingungen)
- Koloniale Raubkunst im Humboldt Forum (Auszug aus einem Artikel)
- Robert-Koch-Institut (RKI) (Auszug aus der Internetseite des RKI)
- Special Olympics 2023 (Rückblick des Organisationskomitees)
- Volksentscheid Berlin 2030 klimaneutral (Auszug aus dem Aufruf)
Wie können wir die Qualität der Übersetzungen von GPT-4 und Bard vergleichen? Als Maßstab ziehen wir die neue internationale Norm für Einfache Sprache heran. Die Internationale Organisation für Normung (ISO) hat im Juli 2023 den ersten Standard für Einfache Sprache verabschiedet. Diese Norm (DIN ISO 24495-1) leitet unsere nachfolgende Analyse.
B. Können Bard und GPT-4 die Anforderungen der DIN ISO für Einfache Sprache erfüllen?
Die DIN ISO enthält vier Grundsätze für Texte in Einfacher Sprache:
- Die Leserschaft erhält, was sie braucht. (Relevanz)
- Die Leserschaft kann leicht finden, was sie braucht. (Auffindbarkeit)
- Die Leserschaft kann leicht verstehen, was sie findet. (Verständlichkeit)
- Die Leserschaft kann die Informationen einfach verwenden. (Anwendbarkeit)
In diesen Grundsätzen steht die Leserschaft im Mittelpunkt. Auf sie ist die Einfache Sprache ausgerichtet. Das gilt zwar vor allem für neu verfasste Texte. Doch auch Übersetzungen sollten sich der Leserschaft so weit zuwenden, wie es der Ausgangstext ermöglicht. Nachfolgend werden wir prüfen, wieweit die Übersetzungen von Bard und GPT-4 die Grundsätze der Einfachen Sprache erfüllen.
1. Relevante Aussagen
Was wollen die Leser erfahren? Was sollen sie wissen? Was ist wichtig? Diese Fragen sollten die Übersetzung in Einfache Sprache begleiten. Sinnvoll ist, Wichtiges genauer zu erklären und Unwichtiges wegzulassen. Prüfen wir also, wie die beiden KI-Programme mit relevanten Aussagen umgehen. Zunächst beleuchten wir einige typische Beispiele.
(a) Thema: PayPal-Käuferschutz
Bei diesem Thema konzentrieren GPT-4 und Bard die Übersetzung auf wesentliche Aussagen, dabei formuliert GPT-4 verständlicher als Bard. Häufig übernimmt Bard abstrakte oder fachliche Ausdrücke vom Ausgangstext. Sie sind zwar relevant, aber für die Leser nur schwer erschließbar. Auffällig ist zudem, dass Bard die Information mitunter stark verkürzt. Hier ist ein Beispiel:
Ausgangstext: Diese Ausgangsentscheidung von PayPal gilt als endgültig, Sie können allerdings dagegen bei PayPal Widerspruch einlegen, wenn Sie über neue oder stichhaltige Informationen verfügen, die zum Zeitpunkt der ursprünglichen Entscheidung noch nicht vorlagen, oder Sie der Meinung sind, dass die Entscheidungsfindung fehlerhaft war.
GPT-4: [Ob du Geld zurückbekommst, entscheidet PayPal.] Ihre Entscheidung ist erstmal endgültig. Aber du kannst etwas dagegen sagen. Zum Beispiel, wenn du neue Infos hast oder denkst, dass sie einen Fehler gemacht haben.
Bard: Wenn du mit der Entscheidung nicht einverstanden bist, kannst du Widerspruch einlegen.
(b) Thema: Volksentscheid „Berlin 2030 klimaneutral“
Der Ausgangstext ist voll von technischen Details und daher schwer verständlich. Die Frage ist hier: Welche Informationen sind relevant, welche verzichtbar? Das folgende Beispiel zeigt, dass GPT-4 und Bard unterschiedlich vereinfachen:
Ausgangstext: Stimmberechtigt für den Volksentscheid sind alle Personen, die auch zur gestrigen Abgeordnetenhauswahl wahlberechtigt waren, sofern sie nicht aus Berlin wegziehen.
GPT-4: Wer darf abstimmen? Alle, die auch bei der Wahl gestern dabei sein durften, wenn sie noch in Berlin wohnen.
Bard: Alle, die auch bei der Wahl zum Abgeordnetenhaus abstimmen konnten, dürfen auch bei diesem Volksentscheid abstimmen.
GPT-4 erklärt den Vorgang leicht verständlich, lässt jedoch einen Fachbegriff (Abgeordnetenhaus) weg. Bard wählt die wichtigste Information aus, verzichtet aber auf ein weniger verständliches Detail (wohnhaft in Berlin).
(c) Thema: Raubkunst im Humboldt Forum
Im Ausgangstext wird ein brisantes Thema angesprochen. Wie lässt sich das in Einfache Sprache übertragen? Auch hier gehen die beiden KI-Programme unterschiedlich vor:
Ausgangstext: 1903 wurde das „Luf-Boot“ von einem deutschen Kaufmann der dortigen Handelsniederlassung Hernsheim & Co nach bisheriger Lesart „erworben“ und an das Berliner Museum für Völkerkunde verkauft. Dokumente über diesen „Erwerb“ gibt es nicht.
GPT-4: Ein Deutscher hat das Boot dann gekauft und es nach Berlin gebracht. Wie das genau passiert ist, weiß man nicht.
Bard: 1903 wurde das Luv-Boot von einem deutschen Kaufmann gekauft und an das Berliner Museum für Völkerkunde verkauft. Es gibt keine Dokumente über den Kauf.
GPT-4 übermittelt das komplizierte, aber relevante Detail leicht fasslich an die Leser. Bard gibt die bloßen Tatsachen wieder, ohne deren Brisanz anzusprechen.
Fazit
# Bei den KI-Übersetzungen fällt auf, dass sie kürzer als die Ausgangstexte sind: Wenn wir die Gesamtzahl an Wörtern vergleichen, erreichen die Übersetzungen von GPT-4 etwa 80 Prozent des Ausgangstextes; bei Bard sind es 55 Prozent. Das heißt, Bard tendiert mehr als GPT-4 zur zusammenfassenden Übersetzung. Dabei werden auch relevante Details weggelassen.
# GPT-4 übersetzt komplizierte Textstellen gut lesbar, besonders auf erzählende Weise. Allerdings vereinfacht es den Text mitunter so weit, dass Informationen verloren gehen. Bard hingegen filtert aus komplizierten Textstellen die hauptsächlichen Informationen heraus, teilweise wörtlich, und lässt schwierige Aspekte weg.
# GPT-4 überträgt den relevanten Inhalt weitgehend zuverlässig; Bard übergeht teilweise relevante Inhalte oder gibt sie nicht korrekt wieder. Interessanterweise bestätigt Bard unter jedem Text, dass „alle wichtigen Informationen enthalten sind„. Aus dieser Anmerkung lässt sich schließen, dass die KI auf inhaltliche Relevanz trainiert ist (und offenbar noch weiter trainiert werden muss!).
2. Auffindbare Informationen
Wie können Leser schnell finden, was im Text wichtig ist? Auf drei Aspekte kommt es uns an:
Erstens sollte die wichtigste Mitteilung zum Thema gleich am Anfang stehen (statt einer weitschweifigen Vorbemerkung). Bei unseren Tests beginnen bereits die Ausgangstexte mit relevanten Aussagen, und die Übersetzungen übernehmen diesen Einstieg.
Zweitens sollte der Text so geschrieben sein, dass die Leser leicht erfassen können, was wichtig ist (statt sich in nebensächliche Details zu verlieren). Günstig dafür sind logisch aufgebaute Texte, die den Leser schrittweise zu den relevanten Aussagen führen. Diese Schreibweise findet sich vor allem bei GPT-4, verbunden mit einem eingängigen, erzählenden Stil.
Drittens sollten die wichtigen Inhalte des Textes klar zu überblicken sein. Das kann man beispielsweise mit der Anordnung des Textes oder mit hervorgehobenen Textstellen erreichen. Bei unseren Tests sind die Ausgangstexte reine Fließtexte, nur durch Absätze gegliedert. Die Übersetzungen hingegen unterscheiden sich deutlich:
GPT-4 übernimmt das Format der Ausgangstexte, einschließlich der Absätze. Nur gelegentlich sind Aussagen durch Anstriche oder Punkte gegliedert. Bard hingegen gestaltet viele seiner Übersetzungen so, dass die Leser wichtige Inhalte schnell auffinden können. Hier sind einige Beispiele von Bard:
(a) Informationen im Frage-Antwort-Stil
Wie funktioniert der PayPal-Käuferschutz?
Wenn du einen Anspruch auf den PayPal-Käuferschutz hast, bekommst du den vollen Kaufpreis und die ursprünglichen Versandkosten zurück.
Dieses FAQ-Muster ist gut bekannt und aktiviert die Leser.
(b) Informationen mit Anstrichen oder Punkten
Hier sind die Bedingungen für den PayPal-Käuferschutz:
– Der Artikel muss bei PayPal gekauft worden sein.
– Der Artikel muss nicht angekommen [sein] oder nicht der Beschreibung entsprechen.
– Du musst den Artikel innerhalb von 180 Tagen nach der Zahlung melden.
Aufzählungen sind für Textteile oder als Zusammenfassung sinnvoll. Wird jedoch der gesamte Text so aufgebaut, ist er schwerer lesbar als ein zusammenhängender Fließtext.
(c) Zwischenüberschriften
Die Spiele waren toll
Die Stimmung war toll. Die Athletinnen waren begeistert. Die Zuschauerinnen haben gejubelt. Es war ein magisches Erlebnis.
Die Spiele waren wichtig
Die Spiele haben gezeigt, was alles möglich ist. […]
Diese Überschriften vermitteln hier den Verlauf und die hauptsächlichen Eindrücke eines Ereignisses.
(d) Kurze Absätze mit fett gedrucktem Anfangssatz
Das RKI macht auch Forschung. Es untersucht, wie Krankheiten entstehen und wie man sie behandeln kann.
Das RKI berät auch die Regierung. Es hilft der Regierung, Entscheidungen zu treffen, um die Gesundheit der Menschen zu schützen.
Der erste Satz enthält jeweils die wichtigste Aussage. Allerdings ist der weitere Inhalt der Absätze sehr knapp. Bei manchen Absätzen wiederholen sich auch Aussagen. Mit dieser Struktur ist Bard teilweise überfordert!
(e) Hervorgehobene Zeitangaben am Anfang der Absätze
Heute beginnt die PIN AG mit der Zustellung von Briefen an alle Berliner, die abstimmen können. […]
Ab heute kann man einen Briefwahlschein beantragen. Das geht online oder mit einem QR-Code auf der Abstimmungsbenachrichtigung. […]
Diese Zeitangaben regen zum Lesen und Handeln an.
Fazit
Bard kann Texte vielfältig gestalten: mit hervorgehobenen Informationen, Zwischenüberschriften und Frage-Antwort-Muster. Zudem bietet das Programm für jede Übersetzung drei Versionen an. Mit seinen gestalterischen Mitteln macht Bard die Leser aufmerksam, beeinträchtigt jedoch mitunter den Lesefluss. GPT-4 übernimmt zumeist das Format der Ausgangstexte. Dabei lenkt das Programm die Aufmerksamkeit eher indirekt, indem es die Übersetzung klar und logisch aufbaut.
3. Verständliche Texte
Können die Leser die Texte leicht verstehen? Das ist am besten zu erreichen, wenn die Texte einfach strukturiert sind, das Sprachniveau der Leser treffen und gebräuchliche Wörter enthalten. Unter diesen drei Gesichtspunkten haben wir die Übersetzungen von Bard und GPT-4 analysiert. Hier sind die Ergebnisse.
(a) Einfache Textstruktur
Für den Vergleich der beiden Modelle eignet sich die Software TextLab von H&H Communication Lab GmbH. Diese Software verwendet den Hohenheimer Verständlichkeitsindex (HIX). Dieser Index berücksichtigt vor allem die Länge von Wörtern, Sätzen und Satzteilen. Er misst die Verständlichkeit von Texten auf der Skala von 0 bis 20. Je höher der erreichte Wert, desto leichter verständlich ist der Text. Ab HIX-Wert 10 ist ein Text verständlich; etwa ab HIX-Wert 16 beginnt die Einfache Sprache.
Sehen wir uns die Testergebnisse in der folgenden Grafik an. Hier sind die 5 Ausgangstexte und die KI-Übersetzungen jeweils insgesamt erfasst: mit ihren durchschnittlichen HIX-Werten.

–
Beide KI-Programme verwandeln die wenig verständlichen Ausgangstexte in Einfache Sprache. Dabei sind die Übersetzungen von GPT-4 leichter verständlich als die von Bard. Das erreicht GPT-4 vor allem mit weniger langen Sätzen (über 15 Wörter) und auch mit weniger langen Wörtern (über 16 Buchstaben). Komplexe Sätze (mit mehr als 2 Satzteilen) sind allerdings häufiger bei GPT-4 anzutreffen.
(b) Passendes Sprachniveau
Was aber hilft ein einfach strukturierter Text, wenn die Leser über unklare Aussagen und unbekannte Wörter stolpern? Diese Aspekte können wir mit der Textanalyse von Wortliga einbeziehen. Hier wird das Sprachniveau der Texte ermittelt: Maßgeblich sind die Textstruktur, aber auch Stil und Grammatik und der Anteil gebräuchlicher Wörter.
Die Niveauskala basiert auf Kriterien des Gemeinsamen Europäischen Referenzrahmens für Sprachen (GER). Dieser Rahmen betrifft zwar vor allem die Fähigkeiten beim Erlernen von Fremdsprachen. Doch er bezieht auch die Qualität von Texten ein, die den Fähigkeiten der Lernenden angemessen ist.
Aufschlussreich hierfür sind die GER-Niveaustufen des Lese- und Hörverstehens. Auf dieser Grundlage hat Uwe Roth die Schwierigkeitsgrade des Textverständnisses zusammengestellt. Aus seiner Erfahrung fängt die Einfache Sprache bei A2 an: mit ganz einfachen Alltagstexten. Sie hat aber ihren Schwerpunkt bei B1: mit Texten in gebräuchlicher Alltags- und Berufssprache. Je nach Textart und Zielgruppe kann die Einfache Sprache auch bis B2 reichen.
Vor diesem Hintergrund haben wir die KI-Übersetzungen auf ihr Sprachniveau getestet. Hier sind die ermittelten Niveaustufen von Wortliga im Vergleich zu den HIX-Werten:
Verständlichkeit und Sprachniveau der Texte
Indexwerte HIX – Niveaustufen Wortliga
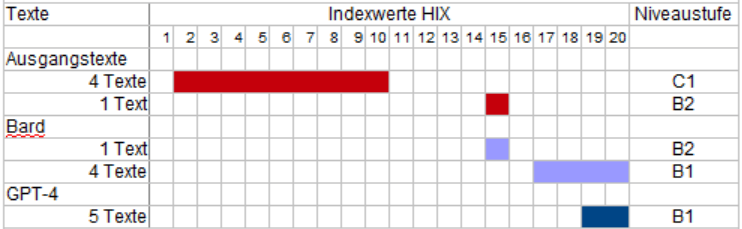
–
Auf der Skala von Wortliga haben fast alle Ausgangstexte das Sprachniveau C1, setzen also fachkundige Sprachkenntnisse voraus. Hingegen erreichen die KI-Übersetzungen zumeist das Sprachniveau B1, das typisch für Einfache Sprache ist. Aber selbst die ‚verständlichsten‘ Übersetzungen mit HIX-Wert 20 schaffen es nicht bis zur A2-Stufe. Das liegt wahrscheinlich an dem zu geringen Anteil gebräuchlicher Wörter. Dieser Vermutung wollen wir in der folgenden Analyse nachgehen.
(c) Gebräuchliche Wörter
Wir nutzen hierfür die Wortlisten des Goethe-Instituts für die Zertifikate auf den GER-Stufen A2 (2000 Wörter) und B1 (3000 Wörter). Der Wortschatz dieser Stufen entspricht einfachen Alltagstexten (A2) und der gebräuchlichen Alltags- und Berufssprache (B1).
In allen Ausgangstexten und Übersetzungen haben wir die Wörter in drei Gruppen unterteilt:
(1) gebräuchliche Wörter = in Liste A2 enthalten
(2) wenig gebräuchliche Wörter = nur in Liste B1 (nicht in A1) enthalten
(3) nicht gebräuchliche Wörter = nicht in den Listen A2 und B1 enthalten
Diese drei Gruppen sind in der folgenden Grafik in den Balken abgebildet: jeweils durch farbige (1), hellgraue (2) und dunkelgraue (3) Abschnitte.

–
Gebräuchliche Wörter überwiegen bereits in den Ausgangstexten. Sie erreichen bei Bard über 70 Prozent und bei GPT-4 über 80 Prozent. Wenig gebräuchliche Wörter machen in allen Texten einen kleinen Teil aus. Stärker vertreten sind nicht gebräuchliche Wörter. Sie umfassen in den Ausgangstexten über 30 Prozent, bei Bard fast 20 Prozent und bei GPT-4 über 10 Prozent.
Die nicht gebräuchlichen Wörter sind eine bunte Sammlung von Fremdwörtern, Eigennamen (wie PayPal), Fachwörtern, Anglizismen (außer bereits üblichen/ leicht lesbaren), abgehobenen deutschen Wörtern und Wendungen, abstrakten Substantiven (außer üblichen wie Gesundheit) und Sprachbildern.
In unserem statistischen Vergleich sind die Wörter allerdings aus dem sprachlichen Zusammenhang gerissen. Manches nicht gebräuchliche Wort könnten die Leser vielleicht aus dem Kontext erschließen. Doch insgesamt erschweren sie das verstehende Lesen. Um diese Hürden zu veranschaulichen, fügen wir ein Beispiel aus der vergleichenden Textanalyse an.

–
4. Anwendbare Informationen
Wie können die Leser Informationen im Text nicht nur verstehen, sondern auch einfach anwenden? Wichtig hierfür sind klare Aussagen, leicht verständliche (oder gut erläuterte) Begriffe und deutlich beschriebene Vorgänge. Hilfreich ist auch, wenn die Informationen direkt an die Leser gerichtet sind: mit der Anrede Du oder Sie, statt einer unpersönlichen Beschreibung.
Drei unserer Ausgangstexte enthalten praktische Informationen. Gelingt es Bard und GPT-4, diese Informationen einfach anwendbar zu übersetzen?
(a) Thema: PayPal-Käuferschutz
Hier geht es um den Anspruch auf Rückerstattung (in allen Texten kursiv gesetzt).
Ausgangstext: Bei Vorliegen der entsprechenden Voraussetzungen haben Sie nach dem PayPal-Käuferschutz Anspruch auf die Erstattung des vollen Kaufpreises für den Artikel zuzüglich der von Ihnen gezahlten ursprünglichen Versandkosten.
GPT-4: Wenn bestimmte Dinge passieren, kannst du dein ganzes Geld zurückbekommen. Auch die Kosten für den Versand.
Bard: Wenn du einen Anspruch auf den PayPal-Käuferschutz hast, bekommst du den vollen Kaufpreis und die ursprünglichen Versandkosten zurück. Du kannst den PayPal-Käuferschutz beantragen, wenn du den Artikel nicht erhalten hast oder wenn der Artikel nicht der Beschreibung entspricht.
Im Ausgangstext ist die Formulierung „Bei Vorliegen der Voraussetzungen“ unklar. Die beiden Übersetzungen mit „Wenn …“ lesen sich zwar leichter, sind aber auch nicht klarer. Erst die Ergänzung von Bard („Du kannst …“) macht deutlich, um welche Voraussetzungen es geht. Diese zusätzliche Information hat Bard allerdings nicht vom Ausgangstext, sondern aus der Originalquelle zum PayPal-Käuferschutz übernommen.
(b) Thema: Volksentscheid „Berlin 2030 klimaneutral“
Der Ausgangstext legt dar, wie die Berliner am Volksentscheid teilnehmen können. Die KI-Übersetzungen geben dieses Verfahren unterschiedlich wieder: Bei GPT-4 ist es detailliert und daher praktikabel beschrieben; bei Bard ist es so kurz zusammengefasst, dass die Leser die Information nicht anwenden können. Aber dafür schließt Bard mit einem praktischen Hinweis:
Wichtig: Die Abstimmungsbenachrichtigung muss bis zum 3. März 2023 zurückgeschickt werden.
Allerdings hat Bard diese Information selbst erzeugt: Sie stimmt nicht. Im Ausgangstext steht nur, dass die Berliner bis zum 4. März einen Brief über die Abstimmung erhalten.
(c) Thema: Special Olympics 2023
Dieser Rückblick endet mit einer Botschaft:
Ausgangstext: Jetzt gilt es, den Schwung der Weltspiele in den Alltag zu tragen.
GPT-4: Jetzt müssen wir das weiter machen.
Bard: Jetzt gilt es, dran zu bleiben. Es ist wichtig, den Schwung der Spiele zu nutzen.
Beide KI-Programme übertragen den bildhaften Ausgangstext in einfache Aufforderungen. GPT-4 spricht Leser mit dem Wir direkt an, sagt aber nicht klar, worum es geht. Bard drückt deutlicher aus, was zu tun ist.
Fazit
Bard gelingt es besser als GPT-4, Informationen einfach anwendbar zu übersetzen. Dabei geht Bard aber teilweise freizügig mit Quellen und Fakten um. Seine praktischen (und leicht auffindbaren) Informationen sollte man sorgfältig prüfen.
C. Wie bewerten wir die Leistungen von Bard und GPT-4 für die Einfache Sprache?
In unserer vergleichenden Analyse haben wir bereits die Vor- und Nachteile der beiden Programme ermittelt: jeweils im Fazit zu den vier Grundsätzen der DIN ISO. Diese Erkenntnisse führen wir jetzt zusammen, indem wir die Leistungen von Bard und GPT-4 bewerten. Dabei verwenden wir die vier Grundsätze der DIN ISO als Kriterien für die Einfache Sprache. Die folgende Übersicht stuft die Leistungen der Programme als „stark“, „mittel“ oder „schwach“ ein.
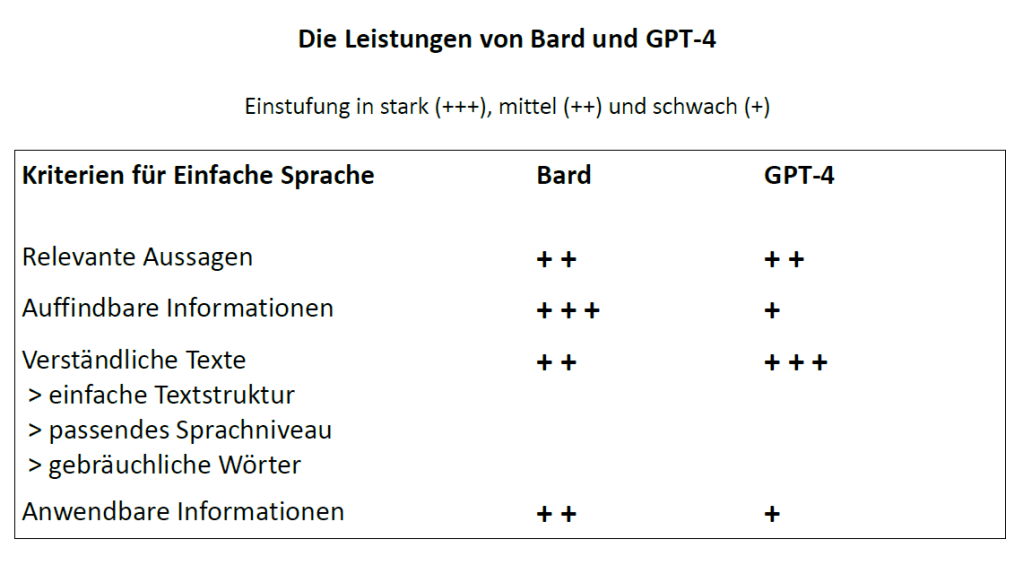
–
Nach dieser Einstufung können wir die Leistungen der beiden KI-Programme zusammenfassen:
Bard gestaltet die Texte leserbezogen, übersetzt leicht verständlich, aber oft verkürzt und nicht immer korrekt. Die Übersetzungen müssen sorgfältig kontrolliert und meist bearbeitet werden.
GPT-4 übersetzt leicht verständlich und eingängig, ohne den Text besonders leserbezogen zu gestalten, und gibt den Inhalt weitgehend zuverlässig wieder. Die Übersetzungen müssen meist nur nachgebessert werden.
Was die beiden KI-Programme leisten, hängt nicht zuletzt von den Aufforderungen (Prompts) ab. Vielleicht sollten sie für GPT-4 und Bard unterschiedlich formuliert werden. Hier lohnt es sich für Sprachprofis, selbst zu experimentieren!
Sabine Manning
PS. Für Anregungen zu diesem Beitrag danke ich insbesondere Stephan Manning, Bettina Mikhail, Uwe Roth und Gidon Wagner (Wortliga).
Bild von VintageSnipsAndClips auf Pixabay
Hinweis: Dieser Beitrag unterliegt der Creative Commons Lizenz. Das bedeutet, dass ihn Interessierte für nicht kommerzielle Zwecke weiterverwenden dürfen. Sie müssen dazu den Autor und den Blog Multisprech (https://multisprech.org/) nennen und dürfen den Text nicht bearbeiten.
